
Refactoring Applications with Domain-Driven Design and Fig Strangler Pattern

Dealing with legacy code is a common task for developers, and in most of the cases it is not a pleasant one, since they didn’t participate in the design of the system, if any design was done at all. Finding yourself in such situation might require that you will engage in some analysis and studies to refactor a legacy application using Domain-Driven Design (DDD) concepts, and possibly apply the Strangler Fig Pattern to migrate from a monolithic application to a microservices architecture.
Embarking in such a journey is not to be taken lightly, and it should be sponsored by the organization and the management you belong to, because it will require a lot of resources and time, and it will be a long-term project: as such, the drivers for this effort shouldn’t be just technical or the desire to use the latest technologies, but the need to improve the business and the organization.
I would recommend some outcomes to argument in favor of this effort:
- Adoption of New Technologies: the legacy application is probably using old technologies, and it is not possible to upgrade them without breaking the application. The new application will be built using the latest technologies, and it will be easier to upgrade them in the future.
- Improve the Readability of the Codebase: the legacy application is probably hard to understand and maintain, especially for newcomers, who would need a lot of time to get familiar with the codebase, resulting in a slow onboarding process. The new application will be easier to understand and maintain, and it will be easier to onboard new developers.
- Improve the Testability of the Codebase: the legacy application is probably hard to test, and it is not possible to write automated tests for it. The new application will be easier to test, and it will be possible to write automated tests for it, resulting in a more reliable application.
- Improve the Performance of the Application: the legacy application is probably slow, and it is not possible to improve its performance without breaking it. The new application will be faster, and it will be possible to improve its performance in the future.
- Improve the Scalability of the Application: the legacy application is probably not scalable, and it is not possible to scale its functions without employing a lot of time, while a new designon will be able to be scaled easily it in the future.
The Legacy Application
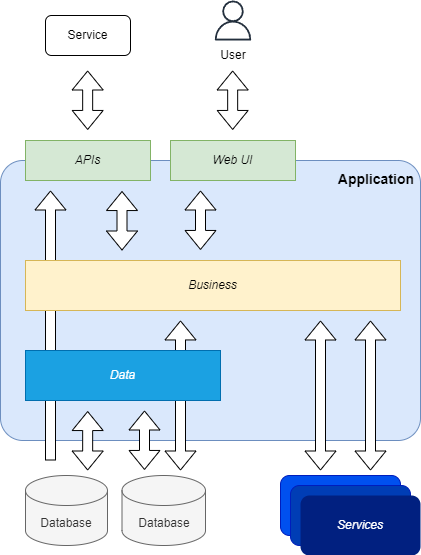
Before the mainstream introduction of patterns and practices like DDD, SOLID, TDD, etc., developers used to write code in a procedural way, with a lot of code duplication, and with a lot of business logic in the UI or presentation (eg. APIs) layer. Furthermore, the lack of analysis of the business domain, the lack of definition of clear bounded contexts, and the lack of communication between developers and domain experts, resulted in a codebase that is hard to understand and maintain.
It is quite common in applications that have been written in such a manner to find the following issues:
- Lack of Separation of Concerns: the codebase is not organized in a way that allows to separate the business logic from the infrastructure, and the business logic is often mixed with the infrastructure code.
- Lack of Abstraction: the codebase is not organized in a way that allows to abstract either the business logic, the data access, or the infrastructure, hindering the possibility to replace or scale them.
- Incorrect Layering: presentation layers often contain business logic, and business logic, or even data access is operated in these topmost layers, making the code not reusable from other applications.
Analysis of the Legacy Application
In most of the cases that require the refactoring of a legacy application, the codebase is not documented, and the developers who wrote it are not available anymore, so the only way to understand the application is to analyze the codebase.
Also, many times the choices of the developers who wrote the application are not clear, and it is not possible to understand why they made those choices: they might not have been informed or trained on the patterns and practices that are used to write maintainable code, or they might have been forced to use a specific technology or architecture by the management.
This analysis should be done by a team of developers, and it should be done in a way that is not disruptive for the business, so it should be done in parallel with the development of new features and bug fixes.
Definition of the Bounded Contexts
Before the refactoring of the legacy application can start, it is necessary to define the bounded contexts of the business domain, and to define the relationships between them.
This aims to define a set of containments for entities, value objects, and aggregates that are logically part of a well-defined context, and that are related to each other, and eventually to define the relationships between these contexts.
For example, in a system that manages the orders of an e-commerce, the bounded contexts could be:
- Orders: The management of the orders places by the Customer of the e-commerce.
- Customers: The management of the entities (individuals or organizations) that acquire products and services of the e-commerce, and it is related to the bounded context of the Orders.
- Products: The products and services that are sold by the e-commerce, and it is related to the bounded context of the Orders and Customers.
Definition of the Entities, Value Objects, and Aggregates
Once the bounded contexts have been defined, it is necessary to define the entities, value objects, and aggregates that are part of each bounded context, so that it is possible to define a coherent model of the business domain.
It is not uncommon that the legacy application analyzed has already some prototypes of entities, and even aggregates, but they are generally not defined in a way that is coherent with the bounded contexts, and they are not related to each other, or even that the developers who wrote the application didn’t know about the concept of entities, and they didn’t define the application objects coherently.
For example, in the bounded context of the Orders, the entities could be:
- Order: The entity that represents an order placed by a Customer.
- OrderItem: The entity that represents an item of an order, and it is related to the Order and Product entities.
While examples of value object could be:
- Amount - The value object that represents the amount of an order, and it is related to the Order entity, calculated as the sum of the amounts of the OrderItem entities.
- Quantity - The value object that represents the quantity of an order item, and it is related to the OrderItem entity.
In this case, the Order entity is to be considered also an aggregate, since it contains the OrderItem entities, and it is the only entity that can be accessed from the outside of the bounded context.
Domain Events and Integration Events
Once the entities have been defined, it is necessary to define the domain events that are related to them, and that are used to communicate the changes of the state of the entities to the other bounded contexts.
The typical approach to design domain events (those exchanged within the same domain) is through the methodology of the delta events, which consists in defining an event for each change of the state of an entity, and that contains the information about the change, not the new state of the entity.
In fact, this allows the minimization of the size of the information exchanged, that other components of the system might not need, and it allows to avoid the duplication of the information, that might be already available in the other components of the system.
These are not to be confused with the integration events, which are used to communicate the changes of the state of the entities to the other bounded contexts, and that contain the new state of the entity: they are richer and bigger, and they often contain the full information of the entity, and not just the information about the change.
Events play a fundamental role in the communication between the bounded contexts, to trigger the execution of the business logic of the other bounded contexts, and they are used to avoid the coupling between the bounded contexts, and to allow the scalability of the application.
The Application Architecture
It is quite often that the architecture of the legacy application is a monolithic one, with a single codebase that contains all the code of the application, and that is deployed as a single unit.
This architecture is not suitable for a complex organization that aims to scale fast, and provide continuous delivery of new features and bug fixes, because it is not possible to scale the application, and it is not possible to deploy new features and bug fixes without deploying the whole application.
Adopting an architecture of the application that is based on microservices, with a set of services that are deployed independently, and that communicate with each other using a messaging system, will allow the organization to scale the application, and to deploy new features and bug fixes without deploying the whole application.
NOTE: Not in all cases this choice is the best one to take, since it might result in an exponential increase of the complexity of the organization, that might not be suitable for companies of just few people.
The Strangler Fig Pattern
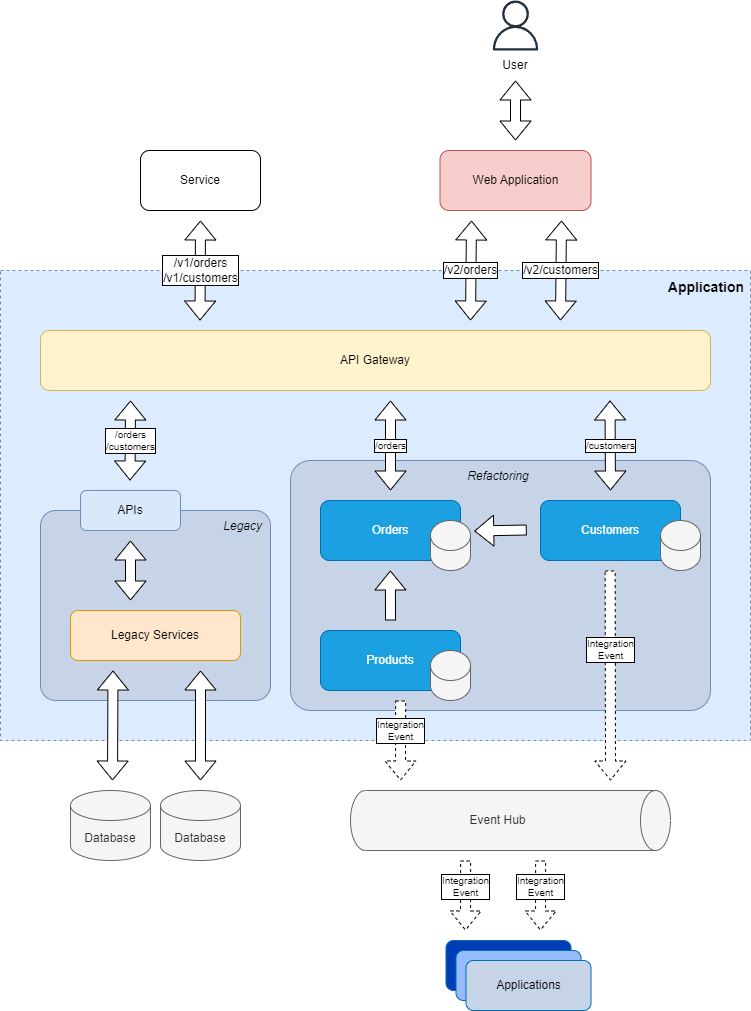
The Strangler Fig Pattern is a pattern that is used to migrate from a monolithic application to a microservices architecture, and it is based on the idea of a strangler fig tree, that grows on another tree, and it slowly strangles it, until it replaces it.
Adopting this pattern requires to create a new application that will replace the legacy application, and to migrate the features of the legacy application to the new application, until the legacy application is not used anymore.
This dynamic is typically required when the legacy application is not possible to be refactored, because it is highly coupled, and it is not possible to extract the features of the application in a way that they can be refactored independently.
The Strangler Fig Pattern in Practice
On a high level, the Strangler Fig Pattern can be implemented with a game of routing:
- Create a new application that will replace the legacy one.
- Use an API Gateway to route the requests to the legacy application or the new one, based on the features and/or versions that have been migrated to the new application.
- Migrate the features of the legacy application to the new one, and update the API Gateway to route the requests to the new application.
- When all the features of the legacy application have been migrated to the new application, the legacy application can be decommissioned.
This approach allows to migrate the features of the legacy application to the new one, without having to stop the development of new features and bug fixes, and without having to stop the deployment of new features and bug fixes.
It has to be clarified that this pattern doesn’t apply only to the migration from a monolithic application to a microservices architecture, but it can be used also to migrate from a legacy application to a new one, even if the architecture of the new application is not a microservices one: this could be the case when it is not possible to evolve the legacy application, and a new one has to be created.
How to Deal with the Human Factor

The refactoring of a legacy application is not just a technical task, but it is also a human one, because it requires to deal with the developers who wrote the legacy application, who might feel under attack, and they might not be happy to see their work being refactored.
It is important to involve the developers who wrote the legacy application in the refactoring process, and to make them understand that the refactoring is not a way to criticize their work, but it is a way to improve the business and the organization: good developers will understand this situation, and they might recognize they didn’t have the knowledge to write a better application, and they might be happy to learn new patterns and practices.
In most of the cases, the codebase of an application is the result of several years of development, by several developers, which was inherited by the current teams, who might have not been happy themselves to write code in that way, but they didn’t have the time to refactor it, because they were busy with the development of new features and bug fixes.